

The art of drawing lines
Are we setting data contracts in the right place?

With many data teams managing hundreds or thousands of data models, the complexity of today’s data stack keeps exploding. To make it all more complicated, data often freely flows through various systems lacking explicit definitions, structure, and guarantees. Yep, I am going there—Data Contracts.
Enough has been said about what the data contract is. I will focus on other perspectives: What role could they play? And what needs to be right so we maximize their value?
Contract’s role in software architecture
Software contracts as a concept can be tracked far in the history of software engineering. When building Synq, we use contracts encoded in Protobuf and gRPC to describe interfaces (APIs) for every cross-system communication to ensure that components of our system keep publishing and consuming data from each other in a reliable way.
In the data world, data contracts emerged with an identical goal: to govern data structure at the point where systems integrate.
From the architecture perspective, they play a crucial role in defining the interface of how systems connect.
Data contracts have the potential to drive data stack architecture; therefore, we must think about where data contracts should be.
It might not be as straightforward as it seems. We could put contracts between technology components like data ingest and a warehouse, but we could also reason differently.
The art of drawing lines
To explain what I mean, I will borrow one of my favorite phrases from Uncle Bob:
Architecture is the art of drawing lines.
It's an elegant way to explain what architecture is and what role interfaces and contracts play. Drawing lines means separating the whole into parts—the “lines” are the interfaces that split the system into components. The fundamental purpose is to isolate changes, where one system can evolve internally without the other. As a result, the team who owns the component can restructure its internals freely. The interface as an architectural constraint gives them the freedom to do so.
But it's not as simple as choosing some interfaces. Or as simple as using existing interfaces. Interfaces put in the wrong places gain you nothing except extra toil to manage more code.
Drawing lines, indeed, is an art.
Two things you need to get right
Before we start setting contracts for interfaces that separate our system into components, we should master two essential skills:
How do we slice systems into components?
How do we ensure that the components keep working together?
The first point is about how we find the right interface. That is not just about the content of the interface but, even more importantly, where the interface should be.
The tendency often is to design the interfaces around technology components (for example, between ingest and a warehouse).
But technology-driven interfaces in complex business systems are rarely the best solution.
This is where we should expand the current data contracts discussion.
We discuss a need for enforceable data contracts between data-producing teams and a data team, assuming we already have the right interface. But maybe we don’t.
Mainly because we’re still predominantly thinking in a technology-centric way.
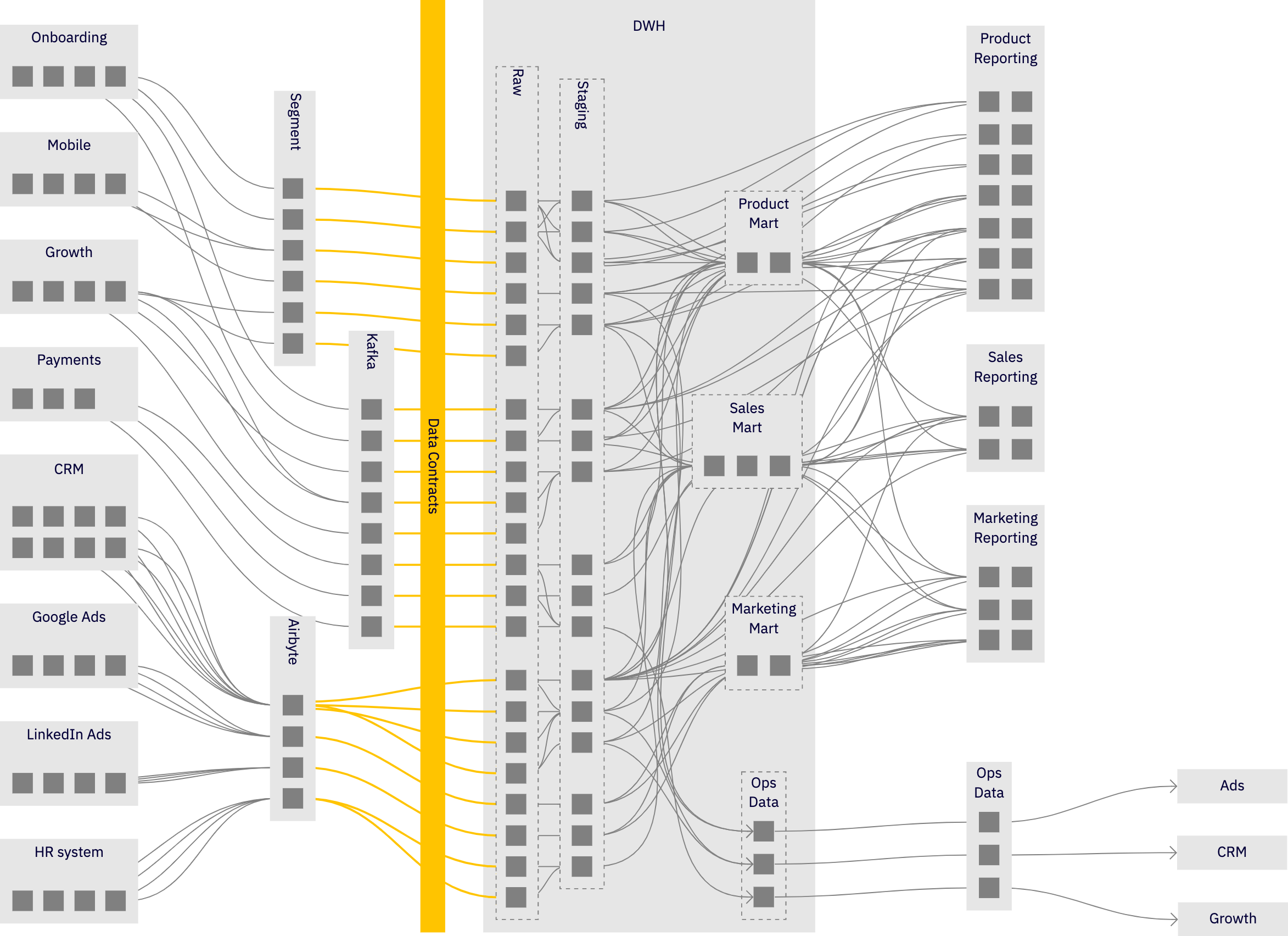
What if there are other interfaces worth governing instead?
—
When reasoning about this topic, my go-to reasons to set interfaces between system components are:
Encapsulation of cohesive logic—Data components get an interface to the rest of the analytics ecosystem, like a few tables and dashboards, and their owners commit to providing a defined quality to the business. The means of delivering these data assets is irrelevant to the consumer. Such components could span multiple technologies (for example, Kafka to ingest events to data warehouses and a set of staging models that apply some cleaning or even joins). The final interface orients around a set of use cases, agnostic to where in the technology stack it is—maybe in front of the warehouse, maybe deep inside of it, maybe in a BI tool.
Separate what changes a lot from what changes less often. James Coplien described this well in his book Lean Architecture: separate what the system is from what the system does. In such a case, the fintech startup could invest a lot of energy in creating a set of well-modeled data streams/tables around their transaction systems with a solid and rich interface used by downstream analytics teams for all sorts of use cases. The use cases can come and go. The core of their business will keep being about payments forever.
Other compelling reasons to set the component boundaries and their interfaces can focus on aligning incentives like ownership, where boundaries reflect how the organization operates—for example, specific business domains.

Reasoning about interfaces from the above principles could also suggest different, potentially more optimal ways data teams could work in the future. Product teams proved cross-functional teams perform better than teams oriented around “layers of the stack” (frontend team, backend team, etc.). Data analysts also frequently work embedded across the business. As the adoption of analytics engineering grows and teams scale, would we see the same trend for analytics engineers, embedding closer with data engineering and software colleagues? What would that mean for where the ideal interfaces should be? The technology we will see emerging to manage contracts and interfaces could make this future more or less difficult.
Finally, technology, as an interface-defining factor, comes last.
When finding the right interfaces, it pays off to think from a business and organizational point of view.
Technology systems boundaries often are not aligned with the directions of change, so such interfaces, despite being well governed, might not do an optimal job of isolating the changes. The interface might tie engineers’ hands and make changes difficult. We should be critical about where we put our interfaces (and contracts that govern them).
—
I will speak only briefly about the second part, managing an interface, as that is where the focus of the data contract discussion is. Plenty of great material has been written about how to write data contracts that describe schema, semantics, owners, SLAs, and other essential aspects of the data.
On top of that, I will highlight two concepts that would fundamentally elevate our ability to govern our data interfaces well:
Ability to encapsulate. The current data stack is highly open. Anything can connect to anything, as the data ecosystem lacks the private concept. Especially if we create data contracts that can live anywhere in the data stack, we would strongly benefit from a mechanism to enforce their usage—by making the internals of modules that power these interfaces entirely private for whoever is its owner. It would allow them to change their code to control the quality of experience provided to the consumer.
Ability to fully test. Validating data contracts at runtime or finding potentially breaking schema changes is excellent. But it's still far from ideal. We would ideally have a complete unit-testing workflow to benefit from the value of data contracts. We create a data-matching input interface of the module and validate that data that comes out is matching output data contract, + we validate that data has exactly the expected values, matching the internal business logic.
Imagine our core fintech system, which contains several inputs, dozens of models, and multiple public interfaces. Its internal logic can accurately model different transactions, refunds, and reverse authorizations and provide a public model with transaction stats per customer. Such a system can be tested by loading mock data and then asserting that the resulting user amounts are correct.
Both of the above techniques would work well hand-in-hand with data contracts.
Drawing the “right” lines is hard.
With the complexity of data systems rapidly growing, we need to emphasize their architecture. It’s one of the hardest things in the software world that often requires tremendous maturity across the entire team. We must architect our systems correctly to ensure that individual modules can evolve and drive the system's value as a whole.
Data contracts should play a role in solving this challenge. Still, without a sound interface, the ability to enforce their usage, and advanced testing, we could miss the opportunity to modularise and strengthen our data systems.
I am excited to follow their adoption, and at the same time, I hope we will evolve the discussion from a concept of data contracts between operational systems and a data warehouse and instead develop a more technology-agnostic approach allowing us to draw the lines in places where we can’t draw them today.