A path towards a data platform that aligns data, value, and people
It's time to move beyond technology layers.

The potential of today’s cloud data ecosystem is compelling: Get data from anywhere in the business and build powerful reporting on top of it. It's now available to any company as a combination of SaaS and open source tools.
And it indeed delivers.
But with great new power comes a new challenge, especially as the company scales.
Here is what happens:
The initially small centralized data team grows. It breaks into multiple teams that embed across the business. Keeping track of changes within the data ecosystem becomes hard.
The number of data use cases grows. Initially, simple reporting expands with new segmentation, additional data fields, filters, or drill-downs. The number of dashboards and reports scales with the business's appetite for more data insights.
The variety of data sources grows. It's no longer a handful of systems that feed the powerful data engine. The company grew and has dozens of sources with hundreds of entities, from CRM, product, billing, support tickets, ad performance, etc.
And the most challenging part? Everything changes constantly.
This, unfortunately, leads to difficult consequences:
Data ecosystems become very complex very fast through thousands of incremental changes. We are underestimating the extent to which systems so complex need to have a robust architecture.
I have one hypothesis why: Moving data around became too easy. We were mesmerized by how fast we got the first few steps done, forgetting we were building the foundation of a vast system.
There are several problems that are very consistent across data teams:
Data lacks intentional design. It is often a byproduct of tools and was often not designed for complex data analytics.
“Data warehouse becomes filled with tech debt the cost of transformations begins to spike exponentially. A query that appears simple might be generated from a table with 30 to 40 JOINs.”
—Chad Sanderson, Link
Data doesn’t align with organizational structures. Think about how much communication and coordination overhead happens in a scaled data organization where data moves through such an ecosystem:
Data moves from Software Engineers / Operational teams (applications) to Data Engineers (integrations) to Analytics Engineers (processing) to Data Analysts (distribution/usage) to Decision-makers (usage).
Data architecture is technology-centric. The layers of the data stack dictate the structure. They emerged to solve various parts of data technology. While many of these products deliver excellent experiences on their own, the technology-aligned stack is not working in great harmony, and the experience of people working across this ecosystem is not great.
Combine it all, and you have a recipe for chaos.
I was frustrated with these problems myself. It opened my eyes to see that this is not a single company problem. This is an industry-wide problem!
We are missing a practice, tooling, processes, organizational alignment, or all of these things. We need to evolve how we think about data systems to deliver on our ambition to maximize the impact of data in scaling companies.
Are Data Products the path forward?
Data mesh, a trend that advocates for new ways of working with data, gained traction last year. It comes with several key concepts, but as I see it, at its core, the message is the following:
Treat data as a product.
A product that has a use case.
A product that has its target audience.
A product that is intentionally designed.
A product that someone owns.
A product that is maintained.
A product, that is well designed and architected.
But as much as this sounds logical, there are many out there (including myself) left with the question: How do I apply this practically after investing 18+ months of work into my cloud data warehouse ecosystem?
Fortunately, data teams have started to embrace this way of thinking. One such team is Whatnot. It was refreshing to hear Stephen Bailey on Coalesce and his talk Smaller Black Boxes: Towards Modular Data Products (well worth the time). Even further, judging from Stephen’s recent blog post, it seems that Whatnot is well underway with a product-centric way of thinking:
“To do this, we reorganized our dbt project, placing each of the 150 data models inside a ‘mart’ with explicit ownership and dependencies. Each mart fits in one of three categories: an application data mart that exposes data from a specific data producer, and contains no logic external to that system; an integrated data mart, that reads from one or more sources and creates useful, integrated views of data; and project-specific data marts, that can be created with short notice and little planning, but which have accordingly smaller scope and loose SLAs.”
—Stephen Bailey

“We organized our dbt Cloud project into modular data marts to better manage their lifecycle and clarify dependencies.”
Stephen also explains how they complement the product-centric design with solid ownership and automated infrastructure in his blog post.
Fade the technology layers to the background
But there is one more step I would like to take to the Data-as-a-Product way of thinking.
One of the most common ways we refer to data platform architecture is via technology layers. I’ve done presentations where I explain data stack in this way too. At the high level, I’ve presented data journeys like this:

Data is lifted from various applications across the business by integration tooling. It’s stored in a data warehouse and processed through stages of business logic before being ready for consumption. End users or automated systems use data through various distribution platforms.
It took me some time to realize that this model is not very helpful for many reasons—it’s too technology-centric and misaligned with organizational structures.
But as Stephen shows, we can look at data architecture differently. And we can do that beyond the data warehouse.
Every data ecosystem comprises assets—database tables, pipelines, data models, data warehouse tables, data lake files, dashboards, reports, and machine learning models. We could organize all assets into products that span technologies and layers of the stack.
Let’s walk through a hypothetical example.
Imagine the following data stack. We have eight source systems with 35 entities plugged via Segment+Kafka+Airbyte to the data warehouse. Warehouse follows a 3-layer model structure organized into raw, staging, and multiple marts that ultimately feed into 24 dashboards for a product, sales, and marketing reporting + 3 reverse ETL syncs.
The diagram looks like this:

Now, let's zoom in on a Growth team. It’s a team in charge of company growth with six engineers, a designer, a product manager, and a product analyst. They use a lot of data themselves, but to ensure that the business has good visibility into what is going on in their world, they would like to produce the following:
Two reporting dashboards with an overview of what is going on in their area—anyone in the business can use them to see growth performance.
Three data feeds materialized in the data warehouse as tables exposing data to the analytics community.
We could highlight growth data products maintained by the growth team in the diagram (green):
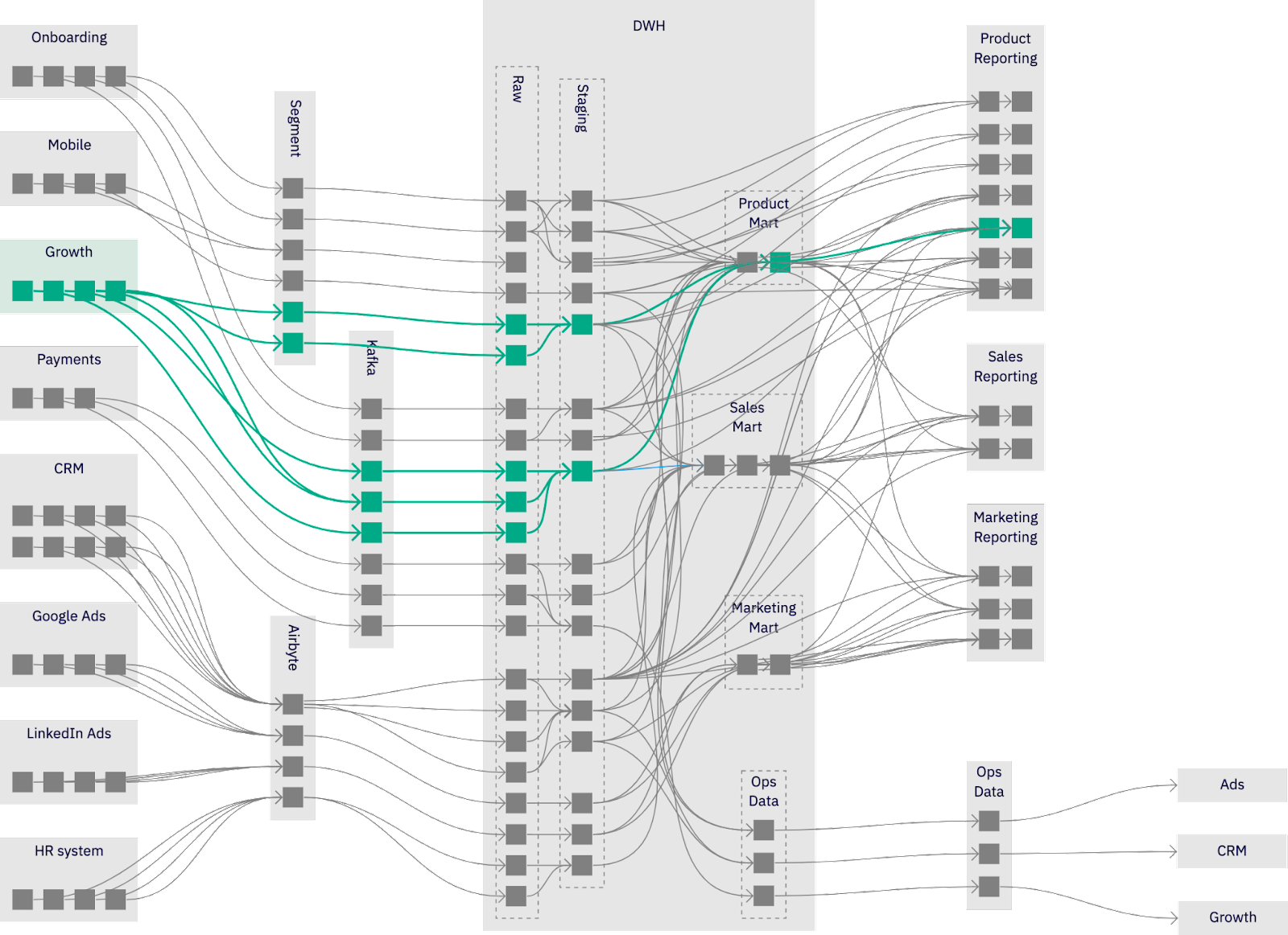
The various artifacts that the growth team wants to share with the business sit on multiple parts of the data stack.
But what if we turn our heads sideways, put technology components to the background and focus on how the data flow? We could carve out the Growth team’s world into a product with five features: three analytical tables and two dashboards.
Conceptually it looks like this, with green boxes highlighting the exposed features that could be used across the company:

This view allows the growth team to overview their data product, regardless of technology layers (indicated in dotted lines within their data product). They could get more directed alerts, usage statistics, explicit dependencies, and the ability to hide the details. The segment events, Kafka topics, and intermediate tables are their implementation details—these are not intended for direct consumption. We can hide a lot away with the appropriate metadata and tools, leaving a clear, explicit interface between the growth team and the rest of the company—3 tables and two dashboards. That’s it.
And it gets even better.
The data product concept cascades through the entire data ecosystem—new products are built on top of existing products, each having the same properties—use case, user, quality, design, and ownership in mind, composed of data assets that live across technology tools and platforms.
In this product-centric model, the technology layers fade to the background. They are just an implementation detail. The architecture revolves around products that compose on top of each other. The products span technology layers as logical groupings powered by metadata.
I’ll leave you with the following picture. It's a different kind of lineage that strips off the underlying details, layers, and tools, simply focusing on data products:
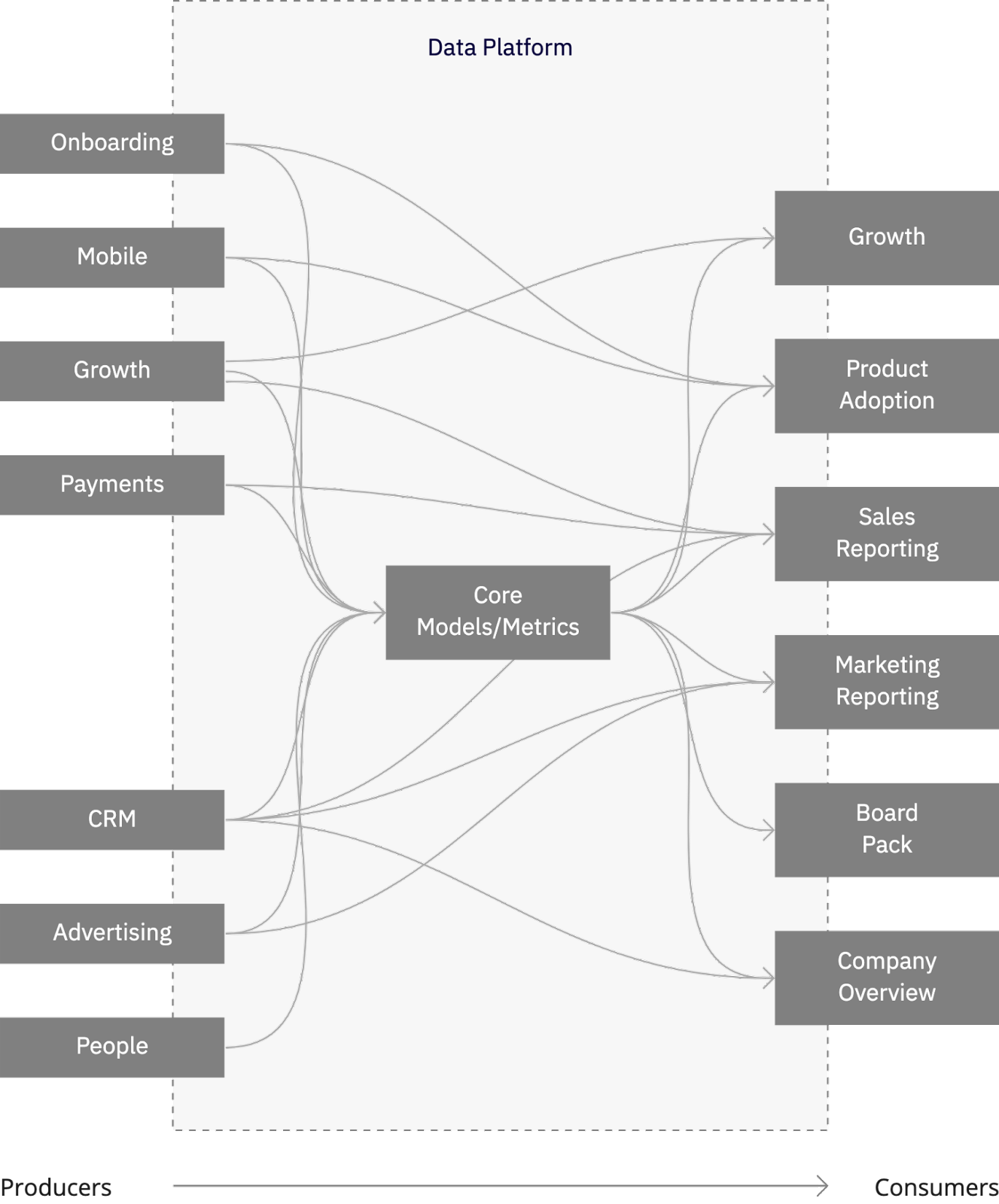
The products are aligned around cohesive data use cases and teams. The owning team decides how the product evolves and what feature it provides to support its use and takes responsibility to ensure it works.
This future with more explicitly and logically organized data could drastically reduce the complexity. It could facilitate new workflows and cleverly involve teams not involved in the data world today. It could support a shift in the company culture that drives data forward.
I am certainly excited about it and planning to spend a decent amount of my time working on making it a reality. Want to join me to geek out about how? I am always happy to hear from other data practitioners solving real-world business challenges using data. Drop me a note at petr@synq.io.
This is great Petr, I'd love to geek out about the solution you're thinking!