A different way to "bundle" Data Platforms
Why should we stop focusing on bundling tools in our data stacks?

As data professionals, we are gradually leaving once market-leading monolithic data platforms behind. We’re moving towards a data stack composed of specialized tools organized into layers created from unbundling BI. The list of layers and other supporting tools is growing, and more layers are under construction.

But some are predicting consolidation or “re-bundling”. There are many reasons why this could be an exciting path to take, ranging from business, potential change in the funding market, suboptimal workflows, and cost. It's a topic I’ve been thinking about too. First, let's visit two different industries that can provide a comparison.
Story of white walls
Three months ago, we bought a house and decided to redo the painting of several rooms as part of a broader renovation. The job was simple—just plain white-colored walls. Imagine my surprise when I found that painting was the most expensive line item of the renovation.
Really?
Over the last two weeks, I’ve learned why. Due to the poor state of the previous walls, various skilled painters have had to strip the room down to the bricks in many places before applying layers of materials. First came multiple types of plaster reinforced by a plastic net, then a filter to absorb the color, and finally, two coats of paint. I was shocked to see how many specialized tools, layers of materials from various vendors, and differently skilled people are needed for this type of job.

It is not how things were done a few millennia back when masonry was invented. Today, one layer is no longer enough. In the language of data debates: the wall was unbundled.
Obligatory Data vs. Software comparison
While the home renovation was a new world to me, I wanted to reflect on a comparison with the one I am intimately familiar with—the software ecosystem. Since I am in the process of building a relatively standard software system, I looked at the set of tools and frameworks I am using for that(this is not an exhaustive list, by the way): GCP, Vercel, Github, Pulumi, Helm, Kafka, Golang, Protobuf, Golang, Typescript, Remix, Radix, Stitches.dev, Visx, React Flow, Snyk, Datadog, Sendgrid, Twingate, Auth0, Kubernetes, Postgresql, Clickhouse, etc.
We could go a layer deeper, to choices I had to make about various libraries. It’s common to use dozens of tools to build software systems. And our data systems are not any simpler than our software anymore.
Why are we expanding our data stack anyway?
The modern data stack today has 29 categories. We had much less complexity, fewer tools, and fewer layers a few years back. But similarly to masonry, painting, and software, the expectations for what we want to create with data have changed.
We are now working far beyond what the previous generation of tools was capable of. We are now well beyond BI. We have introduced many more tools to the data ecosystems aligned with our ambitions.
We’re now talking about real-time and streaming, operationalization of data, ML models embedded in data warehouses, auto-trained ML models, or integrations to hundreds of SaaS tools. Data stack complexity reflects these new expectations. And there is so much more potential for how we can work with our data. As a result, I expect that the stack will keep expanding too.
Why do we want fewer tools?
Coming from the CFO’s office, the primary concern is cost. It's not just a growing cloud platform bill. An increasing number of vendors in the budget are selling subscriptions to their services within the stack. Luckily the market is vibrant, and we have choices. We choose to use either a fully managed or open-source component for nearly every part of the stack.
For the leader in charge of the technology strategy, the next challenge is the overwhelming number of choices. While this topic is non-trivial, I consider this a good thing for the buyer—we simply have options to optimize for our specific needs.
And from the teams working with the data stack, this means learning a lot about how to work well with a broad range of tools.
But while we can work around the cost and sometimes a vast number of choices or need to learn many tools, one concern stands out for me:
In its current shape, the components of the modern data stack integrate poorly. The tools today provide a somewhat disjointed experience. Working across layers is painful.
So is it time to re-bundle?
—
I can hardly see how large-scale bundling can take shape. There are simply too many diverse problems to solve.
No single company can execute the current 29 categories, blending all rich functionality into a single cohesive tool.
That said I still expect two types of bundles.
First, tools for very entry-level use cases. Getting started is an overwhelming challenge for companies that don’t have any data ecosystem. They might prefer a more straightforward all-in-one tool that solves their relatively simple use cases.
The second type of bundle will appear as some players out-execute the rest and spill into adjacent use cases. While this could look like bundling, I would expect this to manifest itself as a multi-product strategy—buy multiple tools from the same vendor.
And so, with limited options for bundles, what can we do to get a better experience with our stack?
Integration masqueraded as bundling
In his “Rebundling the Data Platform” article, Nick Schrock has shown a way. He argues that the current stack is poorly orchestrated: since today’s data stack is composed of many components that predominantly work in batch mode, they need a unified schedule. If this is addressed by each tool separately, the schedules can get tricky, leaving room for temporal inconsistencies.
But the article left me confused. Primarily because of the word ‘rebundling’ in the title. I wasn’t alone:
The challenge is that even with a unified scheduler, nothing gets bundled. All tools are still there; they just operate better together. They have a unified orchestration mechanism.
The path forward with integrated data workflows
Orchestration is not the only concern that goes across the entire stack. Here are a few more - from the conceptual perspective, it looks like this:
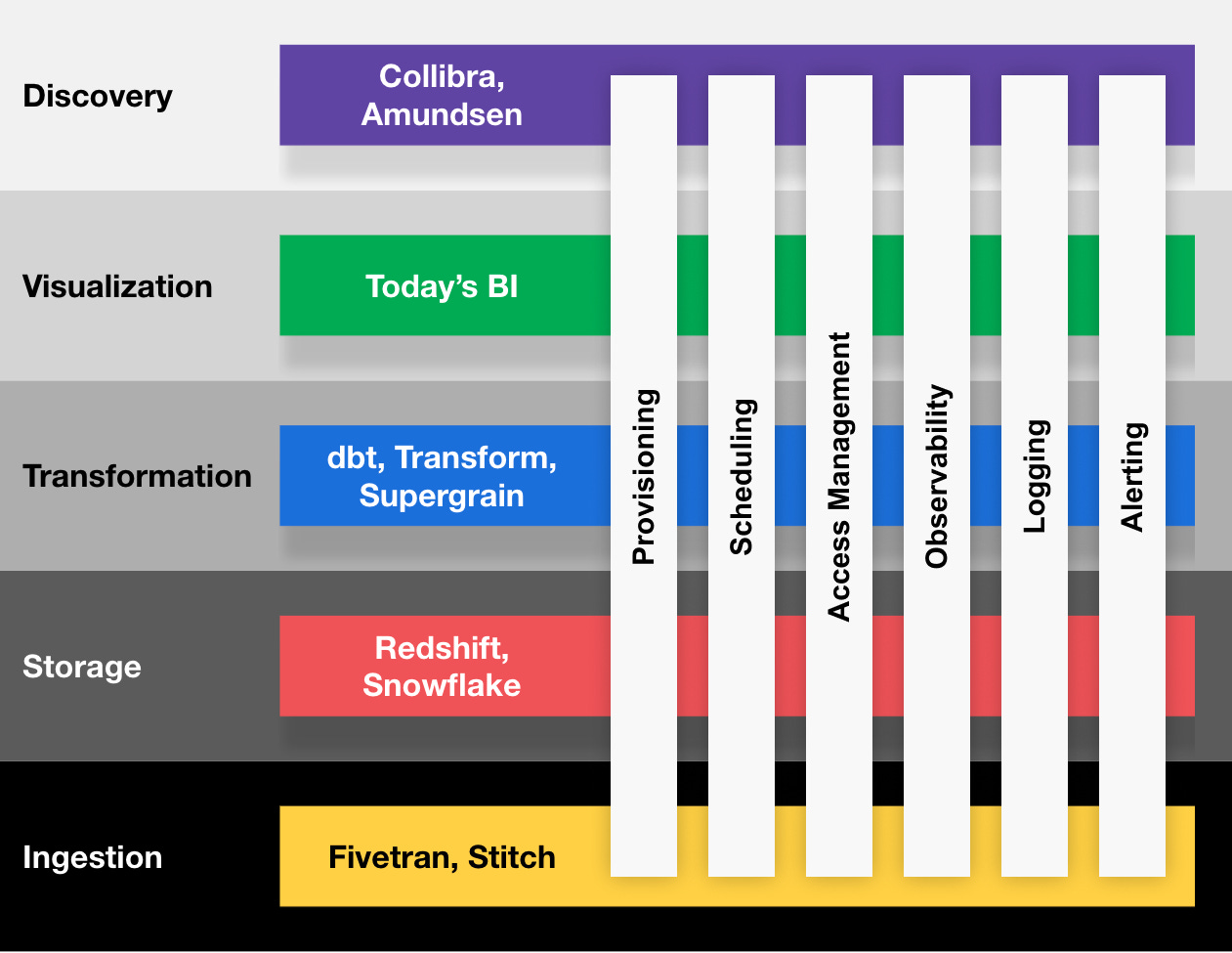
Provisioning—It is not trivial to provision the whole data stack. We have to configure all components to plug into each other, but the process is manual and error-prone.
Access Management—how do we ensure that only the right people can see the correct data and that only the right people can do the right thing across the stack? That is a nontrivial job today.
Observability—We should see the entire system's state and understand how all parts tie together. Many tools provide this information only over a subset of the whole data ecosystem. Understanding the entire stack is challenging.
Logging — Each tool has its specific method of logging. Users who want to understand what happened across various tools have to jump between different interfaces, with each tailor-made. No wonder debugging data issues is so elaborate.
Alerting — Different tools fire all sorts of alerts. Teams have difficulty keeping up with their slack notifications, emails, or unhandled exceptions from various sources. This noise overload increases the risk that they will miss something critical one day.
There are also issues with security, PII governance, and more.
The experience of teams running data platforms depends on their ability to handle the above problems cohesively across the stack.
These problems are hard to solve in isolation within each tool, but Dagster shows the way: We leave existing layers and tools in place, and instead, we facilitate unified experience across all layers of the stack for problems where the cross-stack experience matters.
Does this mean buying or deploying fewer tools? No, not really.
Instead, if the key workflows that need to span across various parts of the stack are integrated for a cohesive end-user experience, the number of tools and layers would be less of a problem. We would tackle the most significant pain point—disjoint cross-layer experience—while keeping the rich ecosystem of choices that work for many expectations, limitations, and use cases.
It’s what I’ve seen in software and over the last two weeks in the house reconstruction too. The number of tools and choices could be a bit overwhelming, but what feels too complex is the result of the industry's maturity, tailoring to a wide variety of needs.
Data is getting there too. We are getting many robust building blocks to compose unique solutions and experiences for our teams, but we should not forget that all the pieces have to be able to play nicely together.
Photo by Henry & Co. on Unsplash
Diagram by Benn from Is BI dead?
Most of the current approaches are automating the existing tools built on data management methods of the past. The science of data management is not fully implemented in these tools and approaches. There are better ways to make life easy for implementers by reimagining data modeling and job building in the modern DW world. Data management systems ignoring "when and what changed in data" as additional information, tend to limit the value of data consolidation. Most modern platforms do not consider "data conformation" as an important element. There are several data warehousing principles that are ignored in these architectures resulting in not being able to obtain answers to questions such as "what is the % of sales increase in Q1 from last year to this year Q1 (before and after re-org)". One of the important aspects of a platform is that data coming from different data sets should always match. If not, how is it different from a cluster of independent/disjointed systems? There is a lot that needs to be done in higher layers beyond Orchestration. Effective Orchestration keeps us sane when doing the actual work.
That is right and integration companies have been making money making connectors. And it used to be very complicated but had simplified in the recent years so now software can emerge to unify. Key may however be how to convince developers who are often in love with a few software/tools they use. Community led/product led growth or private software type of reach, or both?