

The messy core of the Modern Data Stack
[7 minutes read]

More than fifteen years ago, in my early career, I spent a lot of my time building all sorts of systems - mass email schedulers, travel agency booking, or a webshop selling tractors or land mowers. I used the latest version of PHP and PostgreSQL. Back then, as hard as it is to believe, I enjoyed writing the PHP code, learning what it takes to build a software system that can do something useful for clients who are willing to pay for it.
One of the key parts of these systems was SQL code. I must say, it wasn’t my favorite. I did what was needed to get these SQL queries to work. Once they did, I swiftly checked the code into subversion (yes, no git back then, folks) and moved on. A couple of years later, when I switched to Ruby on Rails and Active Record, I was happy to leave the SQL code behind. Back then, at least to me, SQL wasn’t cool.
A few years later, it got even better. With the promise of more straightforward horizontal scaling, the NoSQL movement took off. With CouchDB, Cassandra, HBase, or ElasticSearch, there was no more need for SQL. Yay!
The rise of the Modern Data Stack
After nearly a decade, SQL is back. Driven by innovation in cloud data warehouses such as Redshift, BigQuery, Snowflake, or Firebolt, SQL is firmly established as the dominant language of data.
Do you need to query 1B+ rows of unstructured data? No problem - use SQL. It's accessible, managed, and readily available for anyone.
Built around the cloud data warehouse, the Modern Data Stack has emerged as a set of tools and technologies, helping companies tap into its data at scale. Today, we have tools like Fivetran, Airbyte, or Weld to move data from various systems (yes, your company probably uses 100+ software tools constantly producing data, too) to the data warehouse. We model all this data into carefully crafted tables that plug into BI tools like Looker or Mode. And with the newly established reverse ETL solutions like Census or Hightouch, we can move data back to the operational systems. We have attained a technology stack that allows teams of one or two people to build a complete data ecosystem for their company. Just a few years back, this would take months and a group of experts. Now, it can be done in days.
One of the critical pieces of the modern data stack is DBT. If you still don't use it today, you should; it is fantastic. DBT, the product by DBT Labs (formerly Fishtown Analytics), changed the game. At its core, DBT allows teams to manage SQL like any other code. It is version controlled, code reviewed, and tested with an automated CI pipeline. It makes the analytics workflow feel like software. The rise of analytics engineering! With the modern data stack and DBT at its core, we can work with vast amounts and complexity of data. Just move it to the warehouse and start coding.
In the beginning, it’s clean and straightforward. Join a few tables and swiftly create analytics reports for leadership and management teams. It’s a success! With every report we deliver and every question we answer, a new one pops up. It’s natural; there is always more, so we keep adding. Over a few weeks, we have coded dozens of iterations of our SQL code - adding, changing, and updating the code itself and various definitions. It starts to get a bit complicated. Luckily, because of the power of the cloud data warehouse, everything works without a hick-up when it comes to raw data processing power. The data warehouse does whatever we want. It all works beautifully.
The Catch
It doesn’t take long, and “a bit complicated” turns into “really complex.” In an average business, we have so much data that we are drowning in it. Our initially simple SQL code is now thousands (or tens of thousands) of lines of code (LOC) with complex logic, conditions, edge cases, and concepts.
Can you tell what below 35 lines of SQL code do?
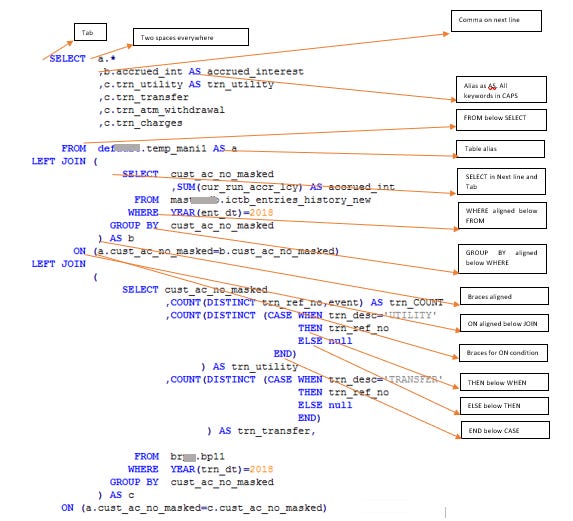
Pff. Not an easy one. Now imagine a hundred of these. It's easy to see how this could get very complicated, very fast.
If we are somewhat advanced, we, at least, version our SQL code and apply tests. We check that specific values are not NULL or that we keep data values in the expected range. Even better, we run alerting to ensure that the data arrives on time and its distributions look as expected.
But despite all the latest tooling, we still end up with a lot of complex code. It’s not uncommon that some teams become too scared to change it. We start to see comments like “do not touch this” or “please don't change this.”
It is BAD. When I see code like that, I am worried, and two particular concepts come to my mind.
The first is spaghetti code.
Spaghetti code is a pejorative phrase for unstructured and difficult-to-maintain source code. Spaghetti code can be caused by several factors, such as volatile project requirements, lack of programming style rules, and software engineers with insufficient ability or experience.
- Wikipedia
It makes other engineers (including our future selves) sad.
The second is technical debt.
Technical debt is a concept in software development that reflects the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer.
- Wikipedia
In more layman terms, you can also say it differently: the code is a mess.
Given that SQL code sits at the very core of our analytics stack, poorly designed SQL code could be a severe problem. It defines how data comes together and how reliable, maintainable, and easy to use the overall data stack is. If the quality of SQL code is poor, the system becomes increasingly hard to operate and evolve.
There is a good reason why I brought up the software engineering terminology. It turns out that a significant portion of time in software engineering is spent on activities to prevent ourselves from creating the spaghetti code and technical debt in the first place, with various degrees of success, of course ;)
Let me explain.
A brief introduction to Software Engineering
I often give introductions to new joiners at our company to explain what software engineering is. This is my second slide:
As software engineers, we write a lot of code. What am I trying to say here?
Well, yes, we do, but there is so much more. I explain software engineering like this: Software engineering is problem-solving, and it usually involves code. It’s a systematic application of engineering principles.
If coding itself is just a fraction of the job, what else do software engineers do?
We plan, design, and prepare before we write code. We often spend hours or days defining coding principles, design patterns, and system architecture. We write design documents to clarify how the new functionality will be built—all of this before we write the first line of code.
On the other end, after we get the code to work, we refactor [1]. We rewrite the code multiple times, using our carefully written tests until we get it to the point that it works and is reasonably easy to read.
We do all of this work to make sure we can keep maintaining our software codebases as they scale. There is nothing worse than getting code to a state where no one wants to touch it.
SQL & Analytics Engineering Today and Tomorrow
Today’s data warehouses can take thousands of lines of SQL code, querying hundreds of tables in one query, delivering results in seconds. Sometimes I wonder if our poorly designed SQL code exists because our data technology stack got too powerful, too quick.
It is not uncommon that in today’s SQL codebases, we tolerate queries and models with thousands of lines of code that have dozens of CTEs, joins, nested queries, intricate conditions, and aggregate functions all mushed together. The warehouse will run it.
But the fact that we can run nearly any SQL at a reasonable speed doesn’t mean that we should! Not even if we manage to hide it under the umbrella of a DBT model and sneak it into the intricate hierarchy of dependent views and tables.
Luckily, we have started the journey of analytics engineering, driven by DBT. But despite the newly established discipline, I sense that we need to accelerate the engineering practice even faster to keep pace with the fast-evolving analytic superpowers of data warehouses.
We need a better design and planning process for writing SQL code, a refactoring workflow to eliminate messy code, and broader adoption of a systematic mindset, slicing the complexity of code into more modular components. The same way as we do in software. We haven’t fully embraced that mindset in the analytics world just yet.
All of this is because data has become too important. And so did the data stack, powered by SQL. We effectively program our business in the data warehouse, using SQL, and the modern data stack continues expanding its use cases, not just in analytics but also operations.
Our ability to successfully run our businesses will increasingly depend on our ability to manage our data stacks. The well-designed and clean SQL code is a critical component at its core. Without the focus on better code, we might fall behind and have a tough time scaling.
With the ever-growing complexity, we need to push on the quality of SQL. We need even more engineering in analytics and less tolerance for poor code.
Are you dealing with messy SQL code yourself? Or even better, did you find good patterns and techniques to prevent it? Please share your thoughts in the comments below or drop me a line at petrjandacz@gmail.com. I’d love to discuss.
I write about data, software, and how we can get the most value out of both.
[1] No-one writes the clean code by Uncle Bob