Should software teams start learning from analytics engineers?
A short story of operational software improved with techniques from data analytics.

We spend a lot of time discussing what analytics engineers should learn from software engineering. But what about the other way?
Reliable data, reliable software
Over the past nine months, I have worked on Synq. This product crunches a continuous stream of queries and organizes them into various storage systems to be served to our customers. They use Synq to build reliable business-critical data.
Since we provide data to others, we also put a premium on the reliability of our platform. You know, to walk the walk.
It’s one of the reasons why we write thousands of unit and integration tests to verify that each component in our system works reliably. For the most part, it works. But as with any sufficiently complex system, it takes a lot of work to cover all the cases. From time to time, we see an unexpected scenario happen, resulting in a bug in our system, which causes incorrect data to be displayed for our customers.
We don’t want that!
A couple of weeks ago, after analysis of one of these bugs, we realized that one type of error is prevalent: We saw customer-facing issues where corrupted or incomplete 3rd party data went through our system undetected.
Sounds familiar?
Analytics lessons learned
Today’s data analytics systems typically load data from dozens of sources and pipe them through complex transformations. Such systems are prone to many issues, which is why the advent of analytics engineering brought testing into this space.
But it works differently.
Instead of testing individual units of transformation in isolation—an approach traditionally used in software—it focuses on testing data at runtime, typically by running perioding queries that check. Various aspects of data are tested at the row or aggregated level. The most common tests verify data freshness, its shape (not null, unique, expected values, etc.), or expectations around the volume. More advanced teams will also plug these metrics into an anomaly detection engine to detect unusual behavior that might be hard to describe by hardcoded rules.
Today most data teams run some combination of data runtime tests. But despite the broad adoption in analytics systems, I typically haven’t seen this type of testing applied in traditional software.
We decided to give it a go.
—
Armed with techniques and tools from analytics engineering, we implemented audit queries on top of our production data. We use Clickouse, so creating a few dozen audit views and a suite of about 50 tests was straightforward.
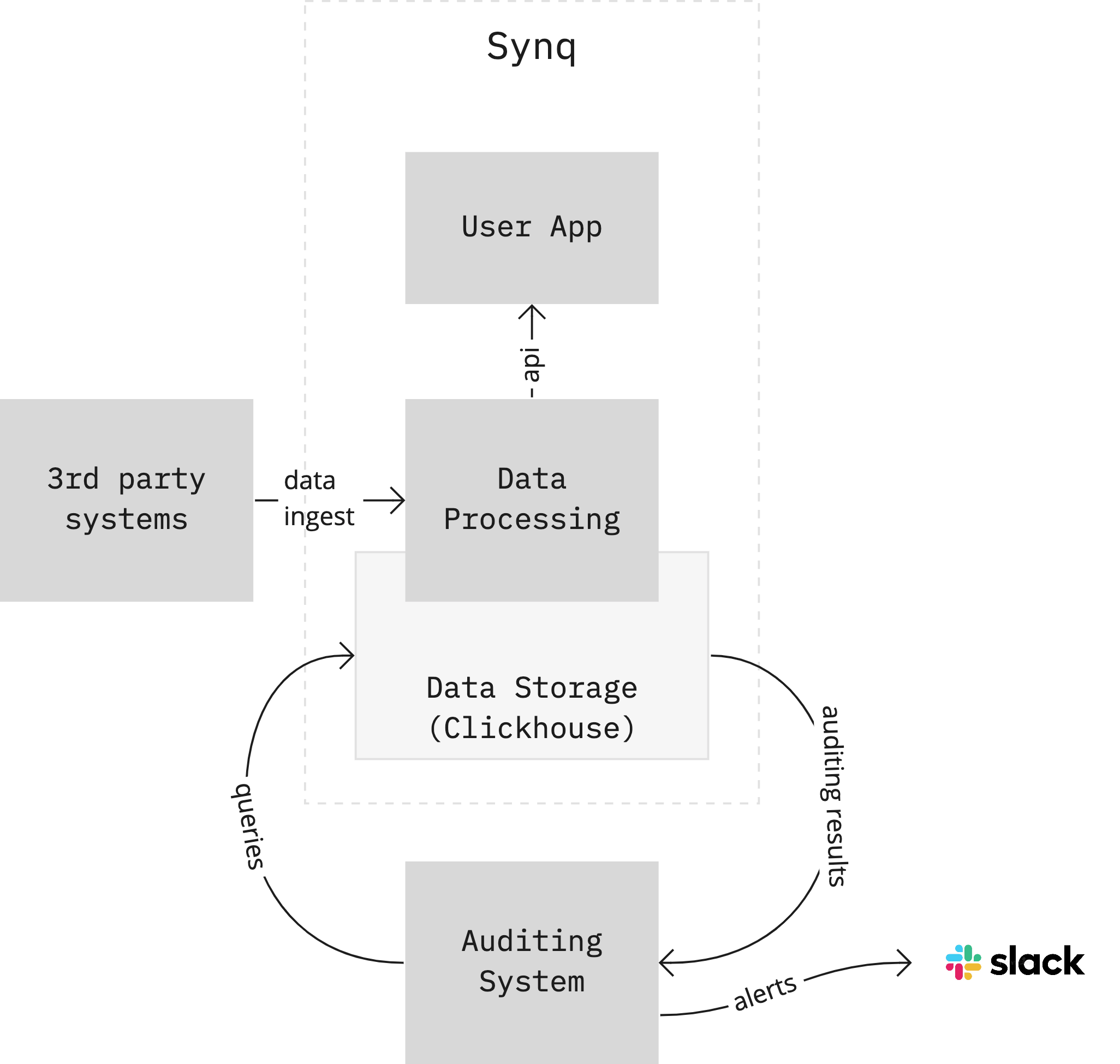
Various queries execute periodically every 5 or 15 minutes to verify our data’s freshness, volume, and shape. We optimized them to be fast, mainly looking at data increments, so the entire test suite runs in a few seconds, barely generating any pressure on our cluster.
With all the tooling for scheduling, query execution, result management, and alerting readily available, setting data runtime checks in operational systems is straightforward.
Since deployment, we’ve detected our customer data missing due to a faulty config of 3rd party system, a cluster of corrupted records that should not have been in our system, or an unexpected drop in data volume in a customer workspace after a configuration change.
Runtime verification of production data is an excellent complement to traditional unit/integration testing.
Using tools and techniques from the analytics world in operational software works.
Identity “crisis”
Working on this system came with a temporary identity crisis.
When using analytics engineering techniques in software, I started wondering what job I was doing. Was it software, data, or analytics engineering? It’s hard to tell as I crossed all boundaries we use to differentiate these engineering fields so many times.
On one side, I understand where these labels come from. Using names like Frontend Engineer, Backend Engineer, DevOps Engineer, Data Engineer, or Analytical Engineer clarifies an area of expertise.
On the other hand, this experience confirmed my belief that its essential to recognize all these fields are just different flavors of engineering. And not just because of the naming semantics.
If you join me in accepting this conclusion, it carries a strong underlying message.
There will be much more practices, processes, tools, and knowledge to share between teams building operational and analytics systems than we might realize today. Especially as practices around the engineering of large analytics systems mature, we should expect and be open to learnings that go both ways.
In the end, it’s all just engineering.