The future analytics developer experience
What can we learn from web developers?

I started my career in tech by building websites nearly 20 years ago. Back then, jQuery and CSS were all the rage, and deployment was done via drag-and-drop copy between the local filesystem and the remote FTP server. That sounds almost comical today.
Last week I had a chance to do a brief visit back to the web development world.
A lot has changed, and it was inspiring.
Modern (web)development experience
As we decided to upgrade our website, we used some of the latest web development tools -- Astro, Tailwind, and Vercel.
It started well. Getting Astro to work with Tailwind was a matter of a few lines of code. The frameworks fluently interplayed, and the code naturally flowed in. When developing, code changes instantly refresh a preview in the browser giving fast feedback. I was constantly in the flow. All I could think about was the target look of the website and the code. Everything else got out of the way.
Once we were ready to deploy, it was live on a global edge network in minutes. The entire website took just a few days to build from scratch, and the workflow was flawless.
This was a great experience, but I’ve learned that today’s web developers are already taking it to the next level: It turns out that everything I did can be done in the browser with an elegant approach.
The entire development server can run with WebContainers in my browser. On my machine! It’s node.js compiled with web assembly, running full stack inside the browser. I decided to try it and managed to spin the entire stack for our website by opening a browser tab. My IDE, terminal, website preview, and developer console blended into one tool, which loaded instantly and had an overall native performance. Due to low-level optimizations that avoid spinning up multiple instances of underlying javascript V8 runtime, it is even faster than my local setup with VS code. This is so powerful!
The ergonomy of such developer experience and the simplicity of its setup is a game changer. The browser allows the development of rich add-ons that can go well beyond VS code, performance exceeds local development, and onboarding new team members is easy; send them a link.
Have a look at StackBlitz yourself. It even works offline.
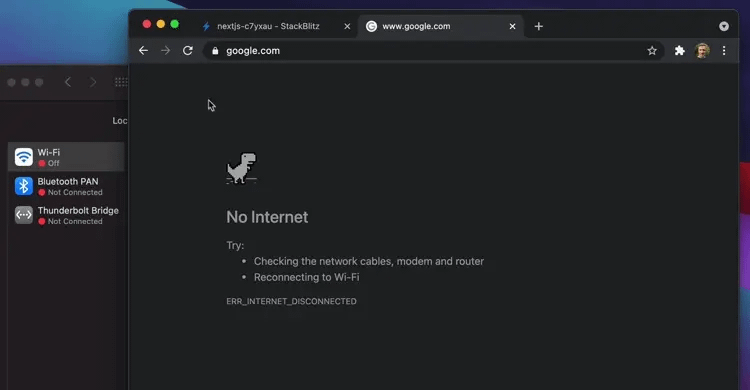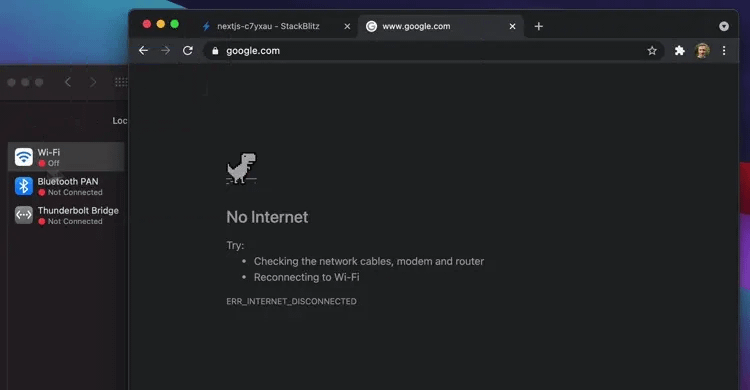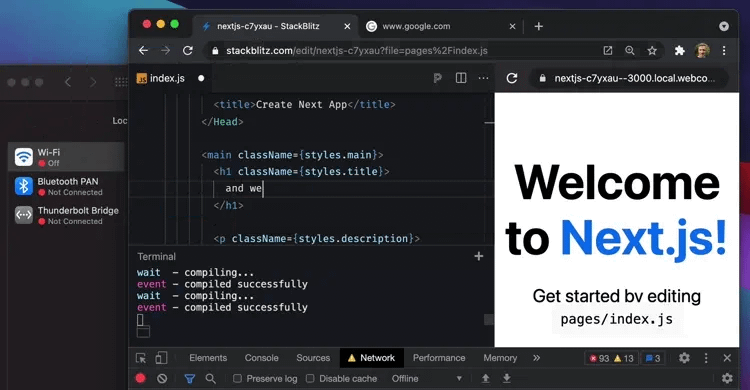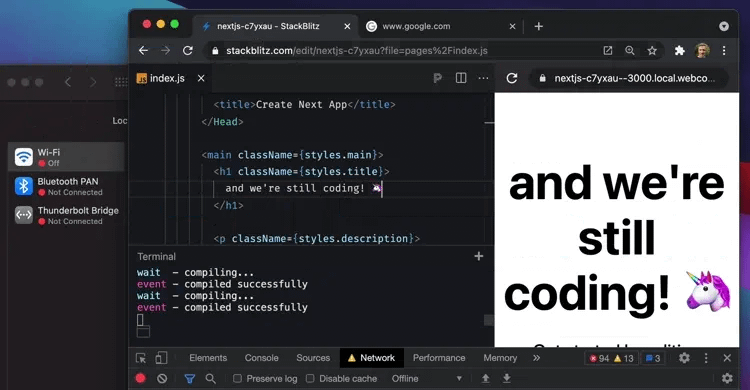
This feels very modern.
Today’s analytics workflow
Working with data analytics today feels different. I could see the contrast clearly because of my work on our analytics stack just a few days before building our website.
We are releasing new analytics functionality in Synq, a set of metrics about runtime, freshness, quality, or volumes of our user’s data. To power our analytics, we had to build a dozen new tables in our data warehouse, Clickhouse.
Under the hood, we use materialized views or dbt to orchestrate data transformations that keep all our tables in sync. On the infrastructure level, this works well. Both Clickhouse and dbt do a great job and keep our data ticking.
But the development workflow for new models was not so fantastic. Let me explain.
—
I got to work on our new analytics data models.
First, I started with a few deep dives into existing data tables, running a few exploratory queries that helped me design the structure of the new models. It was easiest done in the Clickhouse SQL console.
After getting a good grip on data, it was time to write new models.
Because we handle large amounts of data, I materialized models as incremental tables. This enables frequent incremental builds that keep data fresh while being well-optimized for fast queries.
But this comes with a complication. Once I convert SQL to dbt code and add necessary macros, the code is no longer executable in Clickhouse Console. Every time I want to run it, I have to strip dbt syntax, and once I am done with changes, I have to copy-paste them back carefully. This is error-prone and could be more elegant. This problem gets magnified as the project grows. More models, macros, and powerful logic drive me away from raw SQL. That means more copy-paste.
As I continue the project, I frequently jump between several tools. VS code to write code for the models, terminal to manage git, dbt docs with a relatively heavy refresh process, and Clickhouse Console to run SQL code. And a lot of copy-pasting in between.
I realized this experience is identical to how I wrote dbt transformations in 2019, four years ago. How so? So much innovation happened, yet the day-to-day workflow remained more-less the same.
There is so much potential here.
The future experience
If we take inspiration from the web development world, we can imagine an entirely new experience.
Let me be more concrete.
We should have an IDE that allows data practitioners to do their entire workflow as web developers do. The code editor, preview of table data, or lightweight visualizations we can use to spot patterns in data we just built should all be part of a single IDE—no need to jump across multiple tools or copy-paste code to get a single workflow done.
It should be fast, very fast. It needs to feel native. StackBlitz shows the way. The IDE should run on the end user machine. It’s the best way to get the same performance as local IDEs like VS code—no need for spinning up remote servers and sending commands to execute remotely. It is slow and expensive.
It would be accessible to onboard new team members with a near-zero setup. Open a link and get the developer experience as fast as local VS code.
We should optimize the overhead of compiling models to SQL code. Clickhouse can create views or run many queries in around a hundred milliseconds. Yet even creating a simple view still takes 2+ seconds with dbt. That is a considerable overhead. This could be done in milliseconds. If the compiler works fast, the performance of the execution of models would be entirely on the data platform itself. And with a warehouse as fast as Clickhouse, we could get the same performance as web developers—save the model and get an instant preview. The IDE could help us scope our queries throughout development, to keep high performance and avoid excessive data queries.
This is not just about saving a few seconds in the workflow.
If the compilation to SQL runs order(s) of magnitude faster, we could proactively start doing a lot of work behind the scenes. We could get a warning that we are about to query a stale table or a deprecated column or instantly understand the runtime implications of the new dependency. This is entirely possible with fast compilation and fresh documentation, lineage, and observability data embedded into the developer experience.
The IDE can do all this work for us behind the scenes and present concise recommendations to improve our code.

And we could keep going.
The cool thing is that many components of this experience already exist but are fragmented across tools. The technology that could power this experience exists too. But we would have to push on the performance of our tools and focus on the workflow and the developer experience.
Let’s catch up with engineering tools.
When I work with engineers, they are often very demanding of their tools. IDE or terminal that loads slowly (seconds), manual steps that don’t have to be there, or verbose commands are quickly replaced by faster, thought-through, and more ergonomic options.
I don’t see why data practitioners should not be equally demanding, expecting us, data vendors, to obsess about their development experience. They are the customers in the end. As an industry, we should set the bar high, perhaps by taking inspiration from web-development tooling, which is advancing rapidly. It shows that technology that can get the developer experience for data practitioners to the next level is already out there.
PS: I would love to connect if you are a team working on analytics engineering experience. If nothing else, you will have one more fan rooting for your success.
I'm pretty sure that `dbt compile` should give you the SQL generated from the macros.
Not to distract from your core point (which I agree with) but just pointing out that I feel like the compile approach above will solve the current problem you're having.
Take a look at Dataiku. I'm sure you'd be surprised and pleased.