
Building quality from inside
Building quality from inside
And the danger of accidental complexity.

Many teams who have deployed modern data stacks find themselves in the tricky situation of having to engage in continuous firefighting just to keep their system running. As the deployment gets increasingly complex, so too does quality management.
I’ve been there too. As a result, I’ve spent a lot of time finding the best way to avoid slipping into firefighting mode. Does this mean more testing or monitoring anomalies? Or is there a better way to keep quality high?
This is what I’ve found.
Impatient execution
About 2.5 years ago, we decided to build a new reporting stack for the company that could blend data from across the business.
One of my teams was in charge of the underlying infrastructure, ensuring we could bring data together, while another team of business analysts started writing SQL. For the first month or so, things were going just fine. We had integrated a large portion of the requested data across different data source systems. We had successfully deployed data ingest, a mighty data warehouse, and reporting tooling while the analytics team was busy writing SQL in parallel.
One day I got this Slack message:
“Can we materialize one of my queries as a table? BigQuery wouldn’t let me run my query otherwise.”
We were hitting the limits of BigQuery because the query was too complex. It made me wonder: what are we doing to put Google’s flagship data processing engine to its limits?
I looked through the SQL code and found more than 1,500 lines of code in one of the BQ saved queries that further referenced several other views. Woah. That’s a lot of complexity. Do we really need that?
With a freshly deployed dbt, I closed my eyes, said yes, materialized the SQL code as a table, and noted that we needed to deal with this SQL code later.
We never did.
Fragile stack
In retrospect, we made the wrong choice. Looking at 1,500 lines of SQL code in one model should have rung an alarm bell straight away.
1,500 LOC of any code in one blob is terrible. It's too hard to comprehend. It's too hard to evolve. It's too hard to maintain.
Back then, we hadn't realized that we had just laid a foundation for a massively complex system. We had built a foundation that was put together too hastily. It was just a set of SQL scripts stored in git. There was minimal engineering behind it.
The scale of today’s data stack deployments multiplies this challenge by orders of magnitude.
We have reached uncharted territories in how complex and interconnected our data systems are. And we have often turned poorly written SQL scripts to run as a production code hastily.
The speed of innovation further aggravates this.
The entire underlying technology landscape has only been developed over the last few years. This sets a logical limit to how much experience we have in building these types of systems.
It takes years of experience in software to master the art of building large, complex distributed systems. The same applies to data.
As a result, the current state of modern data stack deployments is not great. We have found ourselves in situations where a data stack that was initially reliable and a pleasure to work with no longer feels that way.
New problems appear as the teams, use cases, and inputs scale. Things start to break with unforeseen side effects of changes, and adding new models and use cases feel much more complex than before.
It feels fragile.
The hidden enemy
While the instinct to address quality by adding various testing and alerting solutions to manage the system's failure modes is logical, it doesn’t solve the root cause.
To understand what drives poor quality, we must dig deeper into the system itself.
It turns out complexity has much to do with quality or the effort required to keep the quality high.
Systems with more complexity require exponentially more effort to keep their high quality.
To allow more structured reasoning about this problem, let’s categorize complexity into two main buckets: Essential and accidental.
The system itself drives the essential complexity. As the company gets bigger, it does more stuff; it's getting more complex. If data reflects the business, then the data ecosystem's complexity needs to be there to model the business sufficiently well. That’s the essential complexity.
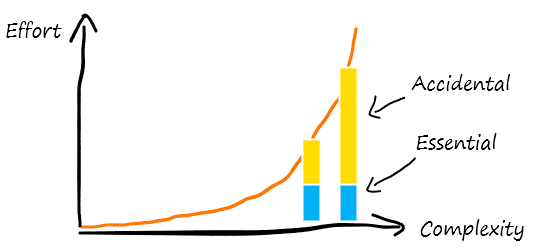
The rest of the complexity is accidental. It doesn’t have to be there, yet it will make its way into the system for various reasons. Perhaps it's an if statement to treat data from two sales pipelines differently, a switch to unify the data from unfinished billing migration, or a patch to re-format product codes due to a bug that was never fixed in the source data. Perhaps it’s just a bit of messy SQL code because no one writes clean code first anyway.
Accidental complexity is a sum of all the shortcuts we have taken. More than a sum—complexity attracts more complexity and compounds in a non-linear way. Every shortcut you take is an invitation to more shortcuts elsewhere.
Taming the complexity
Traditional software is an excellent field to get inspiration from.
Firstly because the software industry has already spent decades developing techniques to tackle complexity. Secondly, because the data stack is a software system.
Two concepts that served me exceptionally well when taming complexity in the software world come to mind. One focused on the complexity of code and one on the system's complexity.
There was a phase in my career when I was obsessed with writing perfect code. The perfect code that is as close as possible to its essential complexity. No accidental complexity is allowed.
The software industry developed several ways to measure code complexity. I’ve used a tool called flog (among others) that is based on a concept called cyclomatic complexity. It measures how many execution branches are there in the code. Every condition like IF/ELSE, SWITCH/CASE, or loop breaks the code's execution into multiple paths. The theory is that more various ways code can execute mean more complexity, which in turn means more ways in which the code can break. The lower cyclomatic complexity meant less room for error.
This taught me an important lesson:
Less complex code, or even better, less code, means fewer potential issues and higher quality. By writing cleaner code and removing duplicated code, one can dramatically improve the reliability of the software system at its very core.
—
The second significant concept is Domain-Driven Design. This focuses on how to structure the system architecturally to best reflect the actual domain being modeled. It comes with concepts that help software teams build well-architected software that models the business well and, as a result, is easier to extend as it evolves.
It has taught me how to think differently about structure. It has taught me how to break complex systems into smaller ones and compose them into one cohesive whole.
As a result, it has taught me how to build higher-quality systems.
Quality via better structure
The above two concepts have an underlying shared idea:
To achieve high quality, we have to build it into the system.
We must tackle the underlying accidental complexity by driving an intentional and well-designed structure. We have to architect our system well and write high-quality code. That is the core of the quality of any software system.
Luckily we are adapting, and many teams I talk to realize that high quality starts with great structure. Teams create “islands” of well-structured data in their warehouses to seed new, much higher standards. I am excited to see their progress in the world in which the spaghetti of dependencies of code we are scared to touch will be history, replaced by more focus on the structure to drive the complexity down and quality up.
In this world, we will not “add” quality to the system. We will build it via intentionally designed architecture and better code.
There is a direct analogy with HW development. Any high complex tool has worse reliability than a simple "clean" design by the theory.
Quality and passion for the highest possible simplicity must be cn integral part of each true developer whatever product is made.
I love the idea of "building quality" into the system and not treating it as a second order problem to solve. There is definitely a role for monitoring, but if you don't have the system built right, you can't - ever - fix it systemically.